《Claude Code 源码解析系列》第5章|Context 治理(选修)
从业界视角补充 Context 管理设计,对比不同 Agent 系统的上下文策略。
《Claude Code 源码解析系列》第5章|Context 治理(选修)
很多人第一次听到 Context Manage,会把它理解成两件事:
上下文窗口大一点。
历史快满了就压缩一下。这个理解不算错,但太窄。
如果只是普通聊天,Context 管理确实主要是在处理聊天历史。但一旦系统变成编程 Agent,尤其是会读文件、调工具、跑命令、写代码、调用外部系统的 Agent,Context 就不再只是一段对话记录,而是模型每一轮工作时能看到的整个现场。
真正的问题变成:
Agent 在工程执行过程中,会不断制造新信息。系统怎么决定哪些信息该进入模型,哪些信息该留在外部,哪些信息要被压缩,哪些信息必须长期保存?
这一篇是选修,所以不只讲 Claude Code。
Claude Code 是一个很好的样本,因为它把编程 Agent 的上下文问题暴露得很彻底:文件内容很长,工具结果很长,测试日志很长,任务也经常持续几十轮。但同样的问题也会出现在 LangGraph、OpenAI Agents SDK、AutoGen、Cursor、Devin、OpenClaw、Hermes 这类不同形态的 Agent 系统里。
只是不同项目的重点不一样:
- Claude Code 更像长任务 CLI Agent(命令行交互式 Agent),重点是工具结果、项目规则、压缩和恢复。
- LangGraph 更像工作流状态机,重点是结构化 State、checkpoint(执行快照)和可恢复执行。
- OpenAI Agents SDK 更像应用开发 SDK,重点是区分本地运行时 context 和 LLM 可见 context。
- AutoGen 更像多 Agent 对话框架,重点是多角色协作、模型上下文和记忆注入。
- Cursor / Copilot 更像 IDE 内的实时助手,重点是低延迟、局部代码片段和检索。
- Hermes / OpenClaw / Harness.io 这类系统则更偏长期运行时、入口控制和企业治理。
所以,Context Manage 不是某个产品里的一个功能点,而是所有 Agent 工程都会遇到的一类底层问题。前一篇已经讲过 Claude Code 自己的压缩链路,这里把视角放宽,看它背后的通用治理模型:
模型是无状态的。
任务是连续的。
信息是爆炸的。
上下文窗口是有限的。
系统必须在每一轮重新整理现场。为了让文章不飘,我们固定一个例子:
用户说:这个项目登录后跳转失败,帮我找原因并修好。一个真正能干活的 Agent,接下来不会只回答一句”你可以检查路由守卫”。它会:
看项目结构
-> 搜索登录相关代码
-> 读取路由守卫
-> 读取鉴权状态管理
-> 跑测试
-> 分析错误日志
-> 修改代码
-> 再跑测试
-> 总结改动和风险每一步都会产生新信息。Context Manage 要解决的,就是让这些信息在长任务里既不断线,也不把模型淹死。
一、为什么 Context Manage 会变成工程问题
先把最底层的事实说清楚:
模型本身每次调用都是无状态的。
它不会天然记得上一轮读过哪个文件,也不会天然知道刚才测试失败在哪里。Agent 看起来像在连续工作,是因为模型外面的运行时每一轮都把”当前工作现场”重新组装好,再发给模型。
普通聊天的一轮调用可以简化成:
用户问题
-> 模型回答但 Agent 的一轮调用更像:
系统规则
+ 项目规则
+ 用户当前目标
+ 历史消息
+ 工具说明
+ 最近工具结果
+ 当前任务状态
+ 压缩摘要
+ 可用外部资源
-> 模型判断下一步这时,Context Manage 要回答的就不是”怎么保存聊天记录”,而是:
- 本轮模型到底该看什么?
- 哪些信息应该每轮都看?
- 哪些信息只在需要时再取?
- 哪些工具结果已经过时?
- 哪些内容太长,需要裁剪?
- 哪些历史可以摘要?
- 压缩后怎么保证任务不断线?
- 多个 Agent 之间怎么隔离上下文?
- 哪些内部状态不能暴露给模型?
这已经是系统设计问题,不是 prompt 文案问题。
如果没有 Context Manage,Agent 很快会遇到几类典型失败。
1. Token 爆炸
工具结果越堆越多,模型请求越来越长。
一次 grep 可能返回几十个匹配点,一次测试可能吐出几千行日志,一个源码文件可能几千 token。长任务跑到后半段,真正占满窗口的常常不是用户的话,而是工具带回来的环境噪音。
(这里有个坑:很多开发者只看对话轮数,觉得”才聊了20轮,窗口应该够”。但实际上每轮工具调用都在往上下文里塞内容,20轮后 token 可能已经爆了。)
2. 上下文污染
旧信息还留在上下文里,但现实已经变了。
比如 Agent 先读过 auth.ts,后来已经改过这个文件,但历史里还保留着旧版本内容。模型下一轮如果基于旧内容继续推理,就会出现一种很隐蔽的问题:
它看起来在认真分析,
但分析对象已经不是当前代码。3. 约束丢失
用户一开始说”不要改 public API”,第十轮以后模型可能忘了。
项目规则说”迁移文件不能手改”,但上下文被压缩后这条规则可能没有进入摘要。于是 Agent 继续执行,看起来每一步都合理,但已经越过了边界。
4. 压缩失忆
压缩不是免费午餐。
粗糙的摘要可能只记录”读了哪些文件、改了哪些代码”,却没有保留:
- 用户真正目标
- 当前卡在哪里
- 哪些方案已经试过
- 哪些约束不能违反
- 下一步应该做什么
这样的压缩会让模型像一个只看过会议纪要的人,知道大概发生过什么,但没有现场手感。
5. 多 Agent 污染
当系统引入子 Agent 或多 Agent 协作后,问题会更明显。
搜索 Agent 读了大量资料,执行 Agent 只需要最终结论。如果把搜索过程的全部草稿都塞给执行 Agent,下游不仅不会更聪明,反而会被噪音带偏。
多 Agent 系统最怕的不是信息不够,而是每个 Agent 都背着别人的中间态往前跑。
二、Context 不是 Prompt,也不是 Memory
讲 Context Manage 之前,先把几个容易混的词拆开。
| 概念 | 通俗解释 | 它回答的问题 |
|---|---|---|
| Prompt | 任务说法 | 我该怎么要求模型? |
| Context | 当前工作台 | 模型这轮到底看到了什么? |
| Memory | 可复用记忆 | 哪些事实要跨任务保存? |
| Transcript | 原始档案 | 完整过程怎样审计和恢复? |
| State | 结构化状态 | 当前任务机器状态是什么? |
| Artifact | 外部产物 | 文件、日志、diff、报告放在哪里? |
可以用一个生活类比:
Prompt 像题目要求。
Context 像桌面上摊开的资料。
Memory 像资料柜。
Transcript 像录音录像。
State 像项目看板。
Artifact 像真正生成出来的文档和代码。很多 Agent 失控,都是因为这些东西混在了一起。
把 Transcript 当 Context,每轮都会 token 爆炸。
把 Context 当 Memory,临时噪音会污染长期记忆。
把 Memory 当 Prompt,模型会把”经验”误读成不可违反的强规则。
把 State 只放在自然语言历史里,长任务一压缩就丢。
所以 Context Manage 的第一条原则是:
不要把所有信息都塞进一条聊天历史。
工程上更稳的做法,是把不同信息放在不同层里,然后在每一轮模型调用前,动态组装本轮需要的那一小部分。
三、先分清动作层和架构层
很多资料讲 Context Management,会先列出一组动作:
Offload:把大对象搬出 prompt
Reduce:裁剪、抽取、摘要
Retrieve:需要时再召回
Isolate:把任务拆到独立上下文
Cache:复用稳定上下文或计算结果这五个动作很有用,但它们回答的是:
上下文太多了,我能做哪些处理?而工程实现还要回答更前面的问题:
这条信息能不能给模型看?
谁比谁更权威?
它现在是热信息还是冷信息?
它应该是原文、摘要、引用,还是结构化状态?
从哪里召回?
怎么压缩才不丢真相?
在哪个边界内使用?这就是本地 wiki 里那篇 Agent 上下文管理:七维模型与上下文操作系统 更有价值的地方:它把 Context Management 从”处理动作清单”升级成了七维架构模型。
动作层像工具箱,七维模型像设计图。
工具箱告诉你有锤子、钳子、螺丝刀;设计图告诉你哪里能敲、哪里不能敲、先装哪一层、出问题时怎么追责。
四、七维模型:把上下文做成可治理工作集
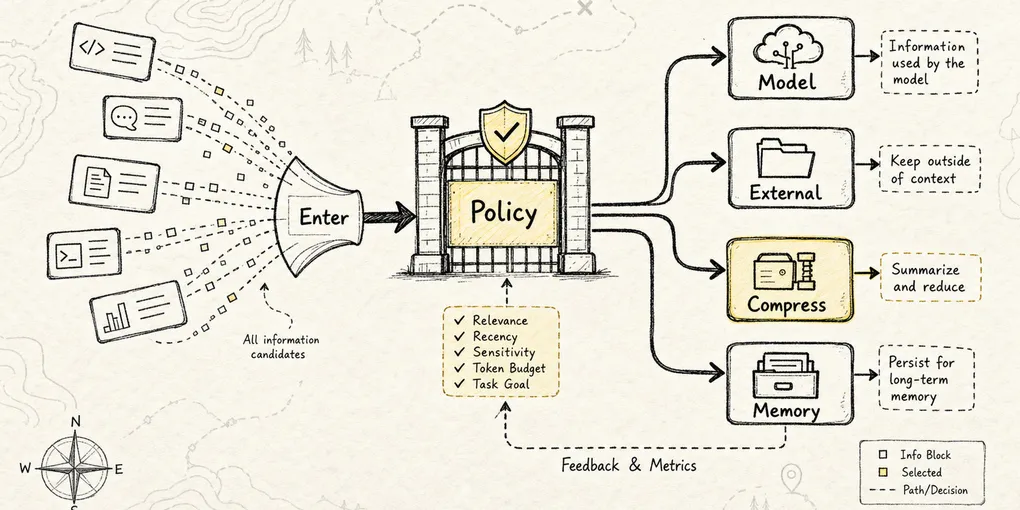
如果把 Context Manager 当成一个真正的子系统,它至少要从七个维度管理信息。
Visibility:哪些信息对模型可见
Authority:冲突时谁更权威
Temperature:信息处在热、温、冷、冻结还是长期记忆层
Shape:信息以什么形态存在
Retrieval:缺信息时从哪里召回
Compression:太长时怎么压缩且不丢真相
Boundary:不同任务、Agent、租户、权限之间怎么隔离这七维不是平行名词,而是一条非常实际的工程链路。
1. Visibility:先决定模型是否应该看见
第一道闸门不是压缩,而是可见性。
上下文大致可以分成三类:
| 类型 | 例子 | 处理方式 |
|---|---|---|
llm_visible | 用户目标、项目规则、关键代码片段、筛过的检索结果 | 可以进入模型上下文 |
runtime_only | API key、权限对象、session、trace、内部依赖、数据库连接 | 只能给工具和运行时使用 |
artifact_ref | 大日志、大文件、网页快照、完整 diff | 原文外置,给模型引用和预览 |
很多 Agent 系统一开始会犯的错,是把”工具拿得到”误认为”模型也该看得到”。
比如 OpenAI Agents SDK 特别区分 local context 和 LLM context,说白了就是在做 Visibility:工具函数可能需要当前用户对象、logger、依赖容器和权限信息,但模型不一定需要看见这些对象,更不应该看到 secret(密钥等敏感配置)。
一句话记:
能不让模型看的,就不要让模型看;能用引用表达的,就不要贴原文。
2. Authority:冲突必须有裁决链
Context 里经常会出现冲突。
用户当前说”直接改 generated 文件”,项目规则说”不要改生成文件”;长期记忆说”用户喜欢 Redis”,当前任务说”不要引入 Redis”;旧摘要说测试已经通过,最新工具结果说测试失败。
如果系统没有显式裁决链,就等于把冲突丢给模型凭语感判断。
一个稳妥的默认优先级可以是:
System / Safety Policy
> Tenant / Organization Policy
> Project Rules
> Current User Instruction
> Current Task State
> Verified Retrieval Result
> Long-term Memory
> Historical Summary
> Raw Old Conversation这条链路的意义不是”所有系统都必须这样排”,而是提醒你:
Authority 必须被设计出来,不能靠 prompt 里多写几句”请遵守”。
Claude Code 的系统规则、项目规则、权限模式、工具安全检查,说白了就是在不同层上共同做 Authority。企业 Agent 里的 RBAC(基于角色的访问控制)、approval(审批流)、audit(审计),则是把 Authority 从 prompt 拉到运行时和组织治理里。
3. Temperature:信息要分冷热层
上下文不是只有”短期”和”长期”两层。
更好用的分法是:
| 层级 | 含义 | 例子 |
|---|---|---|
| Hot | 当前必须使用,默认进 prompt | 当前用户目标、最近失败日志、正在编辑的文件 |
| Warm | 当前可能相关,通常摘要或状态化保存 | 已排除原因、读过文件摘要、当前假设 |
| Cold | 需要时再召回 | 代码索引、文档索引、历史 session |
| Frozen | 完整原始记录,只用于审计和恢复 | transcript、完整日志、网页快照 |
| Long-term Memory | 跨会话稳定事实 | 用户稳定偏好、项目惯例、长期规则 |
这会让 Context Manager 更像一个内存管理器:
Hot 用完后降成 Warm。
Warm 变稳定后可能进入 Long-term Memory。
Cold 被检索命中后升温成 Hot。
Frozen 不进 prompt,但能恢复真相。这也是压缩摘要容易出问题的地方。很多系统把 Hot 现场压成一段 Warm 摘要,却没有保留最近尾巴,于是模型下一轮就丢了现场手感。
4. Shape:同一信息可以有不同形态
不要把所有信息都写成自然语言。
同一段失败日志,可以有很多形态:
| 形态 | 适合什么时候 |
|---|---|
| Raw | 需要逐行分析原始内容 |
| Extract | 只要命令、退出码、错误类型、关键栈 |
| Summary | 旧历史回顾 |
| Structured State | 当前任务状态、失败尝试、下一步 |
| Reference | 原文太长,只保留 artifact ID 或路径 |
| Diff | 代码变更比完整文件更重要 |
| Graph | 模块关系、任务 DAG、表关系 |
比如测试失败日志不一定要整段进入模型,可以先变成:
command: pnpm test auth
status: failed
error: TypeError user.id should be string
file: src/auth/session.ts
test: redirects after login
artifact: logs/test-auth-2026-05-03.txt
next_step: inspect mock user construction这就是 Shape 的价值:
同一条信息,换一种形态,token 成本、可检索性和可靠性都会变。
LangGraph 的 State、Claude Code 的 compact summary、OpenAI Agents SDK 的 tool context、企业 pipeline 里的 execution context,都可以从 Shape 这个维度理解。
5. Retrieval:召回不是只有向量检索
很多人一说召回就想到向量库,但 Agent 的召回路径远不止这一种。
成熟系统至少会有多路召回:
| 召回路径 | 适合什么 |
|---|---|
| Recent Tail | 最近对话、当前工具结果、当前状态 |
| Rule Loading | AGENTS.md、CLAUDE.md、项目规则 |
| Keyword Search | 函数名、报错码、字段名、配置项 |
| Vector / Hybrid Search | 文档语义、相似经验、复杂知识 |
| Tool Search | 工具、技能、插件的渐进式加载 |
| Artifact Lookup | 大日志、大文件、网页结果 |
| Memory Search | 用户偏好、长期事实、项目惯例 |
| Graph Traversal | 模块依赖、任务 DAG、数据库关系 |
代码场景里,关键词、符号、文件路径往往比纯向量更重要。
企业知识库里,混合检索、权限过滤和来源可信度更重要。
多 Agent 场景里,artifact lookup 和结构化 handoff 更重要。
所以 Retrieval 的关键不是”有没有 RAG”,而是:
这类任务缺信息时,最可靠的信息入口是什么?
6. Compression:缩小工作集,不是删除真相
压缩也不只有 LLM 总结。
可以分成几类:
| 压缩方式 | 含义 | 风险 |
|---|---|---|
| Truncate | 直接截断 | 最容易丢关键约束 |
| Extract | 抽取关键字段 | 抽取规则不完整会漏信息 |
| Summarize | 用模型摘要 | 容易摘要漂移 |
| Distill | 归纳成结构化状态 | 需要设计 schema |
| Archive + Ref | 原文外存,只保留引用 | 后续要能 rehydrate |
| Rehydrate | 需要时重新展开原文 | 需要保留可追踪来源 |
更稳的顺序通常是:
先 Offload 大对象
-> Extract 关键字段
-> Distill 成结构化状态
-> Summarize 旧历史
-> 必要时 Truncate压缩最大的风险叫摘要漂移:摘要悄悄改写了用户约束、失败原因或未决问题。
所以压缩结果必须保留:
- 来源范围
- 关键约束
- 已失败尝试
- 未决问题
- artifact 引用
- 下一步
这和 Claude Code 式 compact 的核心是一致的:摘要不是写读后感,而是写交接单。
7. Boundary:隔离是主线程自保机制
Boundary 是最容易被低估的一维。
子 Agent 的价值不只是”并行做事”,而是上下文隔离。
这些任务尤其适合隔离:
- 大规模搜索和资料调研
- 长日志分析和测试排障
- 代码库扫描和网页抓取
- 数据清洗和独立实现子任务
- 高权限工具调用
- 多租户数据访问
边界可以有很多层:
| 边界 | 作用 |
|---|---|
| Thread | 不同会话上下文隔离 |
| Task | 不同任务状态隔离 |
| Subagent | 子任务局部上下文隔离 |
| Tool | 工具权限和输入输出边界 |
| Artifact | 大对象外置,不污染消息流 |
| Permission | 高风险动作审批 |
| Tenant | 不同组织、用户、数据域隔离 |
| Sandbox | 执行环境隔离 |
好的子 Agent 设计应该是:
输入窄:任务 + 约束 + artifact 引用
输出窄:结论 + 证据 + 建议下一步 + 置信度主线程不应该接收子线程的完整过程回放。
没有 Boundary 的多 Agent,很容易从”协作”变成”互相污染”。
五、一个 Agent 执行任务时,上下文是怎么涨起来的
还是看登录跳转 bug 的例子。
最开始用户只给了一句话:
这个项目登录后跳转失败,帮我找原因并修好。如果 Agent 真要解决问题,它可能会制造下面这些上下文:
| 步骤 | 新产生的信息 |
|---|---|
| 看目录 | 项目结构、框架类型、入口文件 |
| 读 package.json | 测试命令、依赖、脚本 |
| 搜索 login | 匹配文件、相关函数、路由路径 |
| 读路由守卫 | 鉴权逻辑、redirect 处理 |
| 读状态管理 | token、user、session 存储方式 |
| 跑测试 | 失败日志、stack trace、测试名 |
| 修改代码 | diff、变更文件、实现假设 |
| 再跑测试 | 新结果、新错误或通过证明 |
这些信息有些很热,有些很快变冷。
当前失败日志很热,因为下一步要根据它定位。
旧搜索结果是温的,因为可能还能参考,但不一定要原样保留。
第一次读取的旧文件内容在文件被修改后就变冷,甚至可能变成污染源。
完整 transcript 很重要,但它是冷档案,不应该每轮完整塞进模型。
所以 Context Manager 要做的不是”全部保存”,而是不断判断:
现在这一步,模型最该看到哪几块信息?这就是上下文治理的核心。
六、工程上会遇到的问题,以及怎么解决
下面把 Context Manage 的工程问题按”症状 -> 根因 -> 方案”拆开。
问题一:模型不知道现场
症状是:Agent 开始猜。
它没读路由代码,却开始改跳转逻辑;没看测试,却说”应该是 token 没存”;没看项目规则,就按自己习惯改目录结构。
根因不是模型不会推理,而是当前 context 里没有足够现场。
解决方式是动态上下文注入:
- 启动时加载项目规则和工作目录信息。
- 当前任务相关文件按需读取。
- 搜索结果先作为候选,不要一次性全塞。
- 工具结果写回消息历史或结构化状态。
- 需要外部知识时通过检索、Web、MCP 或数据库工具召回。
这里的重点是”按需”。
上下文不是越多越好。稳定 Agent 不是看过最多材料的 Agent,而是每一轮拿到最相关材料的 Agent。
问题二:工具结果太长
症状是:token 用量迅速上升,模型越来越慢,最后触发上下文限制。
根因通常不是用户聊太多,而是工具输出太肥。
解决方式是先治理工具结果,再治理聊天历史:
- 给每类工具设置结果预算。
- 长日志只保留错误摘要、关键栈、退出码和相关文件。
- 大文件优先返回片段、行号、符号索引或引用。
- 搜索结果先返回匹配概览,模型需要时再读具体文件。
- 对已过时的工具结果做 snip 或 micro compact。
这点 Claude Code 很典型。编程 Agent 里最容易炸窗口的往往不是推理,而是 Bash、Read、Grep 这些工具返回了太多真实世界的信息。
(实际生产中,我见过一次 find . -name "*.log" 返回了 12MB 内容直接进上下文的惨案。后来加了硬限制:单条工具结果超过 4KB 就自动转 artifact。)
问题三:旧信息污染新判断
症状是:Agent 基于旧代码继续分析,或者重复调查已经排除过的方向。
根因是上下文里缺少”信息时效”。
解决方式是给上下文加生命周期:
- 文件读取结果要记录版本、mtime、hash 或读取时间。
- 文件修改后,旧读取结果应该降权或标记过期。
- 测试日志要关联对应 commit、命令和时间。
- 搜索结果只作为线索,不作为当前事实。
- 关键事实尽量引用来源,而不是只写自然语言总结。
这也是为什么 Context Manager 不只是字符串拼接器。它最好能把信息当成带元数据的对象,而不是一坨文本。
问题四:规则之间冲突
症状是:系统规则、项目规则、用户当前指令、长期记忆互相打架。
比如:
系统要求不能泄漏 secret。
项目规则要求不要改生成文件。
用户当前要求直接修改 generated 文件。
长期记忆说用户偏好快速完成。如果这些都只是自然语言堆在上下文里,模型可能会凭语感选择一条。
解决方式是建立权威层级:
System / 安全策略
-> 组织级规则
-> 项目级规则
-> 当前用户指令
-> 长期偏好
-> 检索和工具结果工程实现上,可以把规则分为:
- 强约束:系统必须拦截或审批。
- 软约束:进入上下文让模型参考。
- 情境约束:只在匹配路径、工具或任务时注入。
这也是为什么大项目里一份超长的 AGENTS.md 或 CLAUDE.md 不一定更好。规则太长、太泛、太冲突,最后会变成上下文噪音。
(实战经验:规则文件超过 500 行时,模型反而开始忽略其中的约束。不如拆成多份,按需加载。)
问题五:压缩后任务断线
症状是:compact 之后,模型还知道大概发生了什么,但不知道下一步该干什么。
根因是摘要只记录”历史”,没有记录”状态”。
好的压缩摘要不是文章总结,而是任务交接单。
它至少应该保留:
用户目标
不可违反的约束
当前阶段
已经读过的重要文件
已经修改的文件
关键判断和证据
失败过的尝试
最近测试结果
下一步建议同时,压缩后最好保留最近几轮原始消息和关键工具结果。
可以理解成:
摘要负责保留主线。
最近尾巴负责保留现场手感。这比”把所有旧历史压成一段话”稳定得多。
问题六:多 Agent 互相污染
症状是:一个子 Agent 的草稿、假设、错误路径影响了另一个 Agent。
根因是所有 Agent 共享一条线性聊天历史。
解决方式是上下文隔离:
- 子 Agent 拿局部任务,不拿全局历史。
- 子 Agent 返回结构化结果,不返回完整思考过程。
- 上游只传递可验证产物、引用和结论。
- 共享状态用 schema 管理,不靠自然语言互相转述。
- 每个 Agent 有自己的工具权限和上下文预算。
复杂任务里,隔离往往比协作更重要。
没有隔离的多 Agent,很容易从”多人协作”变成”多人同时污染同一张桌子”。
问题七:成本和延迟失控
症状是:Agent 能做事,但每一步都慢、贵、啰嗦。
根因是每轮都带了太多固定内容,或者每次都重新检索、重新读、重新解释。
解决方式包括:
- prompt cache:稳定系统提示和工具说明尽量缓存。
- lazy loading:工具详细说明、规则文件、长文档按需加载。
- progressive disclosure:先给摘要和索引,需要时再展开全文。
- local context:运行时依赖和内部状态不送给模型。
- structured state:机器可处理的状态不要变成自然语言 token。
这里最重要的判断是:
大上下文窗口解决容量问题,不解决信息纪律问题。
窗口再大,如果你每轮都塞一堆不相关信息,模型仍然会慢、贵、容易跑偏。
七、不同项目是怎么处理 Context 的
接下来把几个代表项目放在同一张图里看。
这不是为了比较谁更先进,而是为了看清楚:不同宿主环境下,Context Manage 的重点会完全不一样。
1. Claude Code:长任务 CLI Agent 的上下文防线
Claude Code 的典型场景是:
在真实代码仓库里,连续读文件、改代码、跑命令、修 bug。它最突出的上下文问题是工具结果和长任务历史。
所以它的 Context Manage 重点是:
- 项目规则:通过
CLAUDE.md、规则文件、路径范围等方式注入项目上下文。 - 工具结果治理:大文件、大日志、搜索结果不能无限进入消息历史。
- 自动压缩:接近上下文限制时,把历史折成摘要继续执行。
- 会话恢复:transcript、resume、最近尾巴帮助任务不断线。
- 子 Agent 隔离:把搜索、分析、实现等任务分开,降低主上下文压力。
Claude Code 给人的启发是:
编程 Agent 的上下文管理,第一优先级不是长期记忆,而是让工具循环持续跑下去。
因为它真正面对的是:
文件太长。
日志太长。
错误太多。
任务轮次太多。
用户约束不能丢。所以 Claude Code 更像一套”主循环里的上下文治理防线”。
2. LangGraph:把上下文从聊天历史拆成结构化 State
LangGraph 的视角不太一样。
它不把 Agent 主要看成一条聊天历史,而是看成一个图:
节点执行
-> 更新 State
-> checkpoint
-> 下一节点继续它的 Context Manage 重点是:
- State schema:哪些信息是任务状态,要结构化保存。
- Checkpoint:每个 super-step 之后保存图状态。
- Thread:同一个会话或任务的状态序列。
- Time travel:可以回到历史 checkpoint 调试或分叉。
- Fault tolerance:节点失败后从成功 checkpoint 恢复。
这给人的启发是:
不要让聊天历史承担所有状态责任。
如果一个任务有明确步骤、明确节点、明确中间状态,放进 LangGraph 这类状态图里,会比塞在自然语言对话里稳很多。
Claude Code 更像”长任务交互式执行”,LangGraph 更像”可恢复的工作流状态机”。
两者都在做上下文管理,但切入点不同:
Claude Code:先治理消息和工具结果。
LangGraph:先治理状态和执行边界。3. OpenAI Agents SDK:把本地 Context 和 LLM Context 分开
OpenAI Agents SDK 的文档里有一个很重要的区分:
Local context:你的代码和工具运行时能看到的上下文。
LLM context:模型生成时真正能看到的上下文。这个区分非常工程化。
很多开发者容易把 context 理解成”发给模型的东西”。但在真实应用里,有些信息工具需要用,模型不需要看;有些信息甚至不应该给模型看。
比如:
- 数据库连接
- logger
- 当前用户对象
- 权限状态
- 内部依赖
- tool call metadata
- usage 统计
这些更适合放在本地 RunContextWrapper 一类对象里,由工具函数和生命周期 hook 使用,而不是直接注入模型上下文。
模型需要知道的信息,则可以通过几种方式进入 LLM context:
- 放进 instructions。
- 放进本轮 input。
- 暴露成工具,让模型需要时调用。
- 用 retrieval 或 web search 按需补充。
OpenAI Agents SDK 给人的启发是:
Context Manage 的第一步,是区分”运行时需要”还是”模型需要”。
这能避免两种坏结果:
把不该给模型看的内部状态泄漏进 prompt。
把模型不需要看的依赖对象浪费成 token。4. AutoGen:多 Agent 场景里的模型上下文和记忆注入
AutoGen 的典型场景是多 Agent 对话和协作。
这类系统的问题不是一个 Agent 忘不忘,而是多个 Agent 如何共享信息、隔离角色、控制消息历史。
它的 Context Manage 重点是:
- model context:不同 Agent 调模型时看到哪些消息。
- memory:从记忆存储里查相关内容,再更新模型上下文。
- role separation:不同 Agent 的职责和可见信息不同。
- team orchestration:多个 Agent 的消息传递和终止条件。
- context variants:有些场景保留完整历史,有些场景只保留窗口或头尾。
AutoGen 给人的启发是:
多 Agent 系统里,上下文管理首先是边界管理。
一个 reviewer Agent 不应该拿到 executor 的所有工具权限。
一个 researcher Agent 不应该把所有搜索草稿都塞给 writer。
一个 planner Agent 的中间假设也不应该自动变成全局事实。
多 Agent 不是把更多模型放进同一个聊天框,而是给不同角色分配不同上下文、不同状态和不同输出契约。
5. Cursor / Copilot:IDE 场景优先低延迟和局部相关性
IDE 助手的场景又不一样。
它们经常要在你敲代码时快速补全、解释、改写。这里的核心矛盾不是”长任务恢复”,而是:
在很短时间内,找到当前光标附近最有用的代码上下文。所以 IDE 场景的 Context Manage 更偏:
- 光标前后代码片段。
- 当前文件符号。
- import 和类型信息。
- 相似代码块。
- 最近编辑文件。
- 语义索引或增量索引。
它不一定每次都需要完整项目理解。
很多时候,低延迟的局部启发式比重型全局检索更实用。
这给人的启发是:
Context Manage 要服务场景,不要默认追求最完整。
补全任务需要快、近、准。
修 bug 任务需要长链路、工具反馈和恢复。
企业流程任务需要权限、审计和流程上下文。
不同场景的”好上下文”不是同一个东西。
6. Hermes / OpenClaw / Harness.io:长期运行时和治理上下文
再往上一层,Context Manage 会从单次任务扩展成运行时治理。
OpenClaw 更像个人 Agent 的入口和控制平面。它关心的是多渠道消息、自动化任务、设备节点、浏览器和本地能力怎样接入同一套会话系统。
Hermes 更像自我改进的 Agent runtime。它关心的是长期记忆、用户画像、技能沉淀、跨 session 搜索和可复用经验。
Harness.io 这类企业工作流系统更关心 pipeline context、secrets、connectors、RBAC、approval 和审计。
它们的共同点是:
Context 不再只是模型输入,而是整个运行环境的一部分。
到了这一层,Context Manage 要管的东西会更多:
- 谁触发任务。
- 任务来自哪个渠道。
- 当前执行环境是谁的机器或沙箱。
- 哪些 secret 可用。
- 哪些审批已经通过。
- 哪些历史经验可以复用。
- 哪些操作必须被审计。
这说明 Context Manage 的终点不是”更聪明的 prompt”,而是 Agent Harness 的一部分。
八、放在一起对比
可以用一张表把这些项目放回同一个坐标系。
| 项目 / 系统 | 主要场景 | Context Manage 的核心 | 解决的主要问题 | 容易忽略的边界 |
|---|---|---|---|---|
| Claude Code | CLI 编程 Agent | 项目规则、工具结果、压缩、恢复 | 长任务不断线,工具输出不炸窗 | 压缩摘要仍可能丢现场细节 |
| LangGraph | 图式工作流 Agent | State、checkpoint、thread、time travel | 状态可恢复,节点可调试 | 模型输入仍需单独治理 |
| OpenAI Agents SDK | 应用型 Agent SDK | local context 与 LLM context 分离 | 工具依赖、运行时状态、模型可见信息分层 | 开发者仍要设计哪些信息注入模型 |
| AutoGen | 多 Agent 协作 | model context、memory、角色边界 | 多角色消息传递和记忆增强 | 共享历史过多会互相污染 |
| Cursor / Copilot | IDE 实时助手 | 光标附近、相似代码、索引检索 | 低延迟下拿到局部相关上下文 | 不适合默认承担长任务状态 |
| Hermes / OpenClaw | 个人长期运行时 | gateway、memory、skills、session search | 多入口、长期记忆、经验复用 | 长期记忆需要防止陈旧和污染 |
| Harness.io 类系统 | 企业流程 Agent | pipeline context、secrets、RBAC、audit | 把 Agent 放进可治理流程 | 灵活性会受流程边界约束 |
这张表最想说明的是:
不同项目不是在同一道题上给不同答案,而是在不同宿主环境里处理不同上下文压力。
Claude Code 的压力来自长任务和工具输出。
LangGraph 的压力来自状态可恢复。
OpenAI Agents SDK 的压力来自应用运行时和模型输入的边界。
AutoGen 的压力来自多 Agent 协作。
Cursor 的压力来自低延迟代码场景。
Hermes / OpenClaw 的压力来自长期运行和多入口。
企业 harness 的压力来自权限、审计和流程嵌入。
九、如果自己实现一个最小 Context Manager
如果要自己写一个 Mini Agent,不建议一上来就做复杂向量库或多层记忆。
更稳的做法,是把 Context Manager 明确拆成几个小组件:
| 组件 | 责任 |
|---|---|
| Visibility Filter | 判断哪些信息能进模型,哪些只能留在运行时 |
| Authority Resolver | 处理冲突和优先级 |
| Temperature Manager | 管理 Hot / Warm / Cold / Frozen / Long-term Memory |
| Retrieval Router | 决定从规则、关键词、向量、工具、artifact、memory 还是图里召回 |
| Compression Engine | 负责外置、抽取、摘要、结构化和 rehydrate |
| Boundary Controller | 管理 thread、task、subagent、tenant、permission、sandbox 边界 |
| Context Budgeter | 负责 token 预算、选择解释和 ContextPlan |
这样 Context Manager 就不再是”每轮拼 prompt 的一段代码”,而是一个可调试的工作集规划器。
先做最小闭环就够:
1. 所有消息和工具结果进入 transcript,完整保存。
2. 每轮模型请求前,从 transcript / state / memory / tools 里收集候选 context。
3. 给候选 context 打标签:来源、类型、热度、权威性、token 估算、是否可见。
4. 按当前任务选择最相关的一批。
5. 对大工具结果做裁剪或摘要。
6. 保留最近 N 轮原始消息。
7. 旧历史压成任务交接摘要。
8. 压缩摘要里强制保留目标、约束、已做、失败、下一步。
9. 所有压缩前原始内容仍保存在 transcript,方便恢复和审计。一个很朴素的数据结构可以长这样:
type ContextItem = {
id: string
kind: "instruction" | "user_goal" | "tool_result" | "file" | "summary" | "memory" | "state"
source: string
visibility: "llm_visible" | "runtime_only" | "artifact_ref"
authority: "system" | "org" | "project" | "user" | "task_state" | "retrieval" | "memory" | "summary"
temperature: "hot" | "warm" | "cold" | "frozen" | "long_term"
shape: "raw" | "extract" | "summary" | "reference" | "diff" | "structured" | "graph"
boundary: "thread" | "task" | "subagent" | "tool" | "tenant" | "sandbox"
tokenEstimate: number
freshnessTs?: string
conflictKey?: string
confidence?: number
ttl?: string
content?: string
ref?: string
}然后每轮生成一个 ContextPlan:
type ContextPlan = {
selected: ContextItem[]
compressed: Array<{ from: string; to: string; method: "extract" | "summarize" | "distill" | "archive_ref" }>
dropped: Array<{ id: string; reason: string }>
conflicts: Array<{ key: string; winner: string; losers: string[]; reason: string }>
budget: {
total: number
used: number
buckets: Record<string, number>
}
}ContextPlan 的价值是解释性。
当 Agent 失误时,你不只看到”模型答错了”,而是可以追问:
这一轮到底选了哪些上下文?
哪些规则被丢掉了?
哪个工具结果被压缩了?
长期记忆为什么被注入?
某条用户约束为什么没进 prompt?没有 ContextPlan,上下文行为就是黑箱拼接。有了它,Context Manager 才像一个可调试系统。
每轮调用前,Context Manager 做一次选择:
collect candidates
-> remove runtime-only items
-> resolve authority conflicts
-> drop stale tool results
-> prefer hot context
-> compress large items
-> preserve recent tail
-> inject final context伪代码可以这样理解:
function buildContext(task, state, transcript, memory, budget) {
const candidates = collect(task, state, transcript, memory)
const visible = applyVisibilityFilter(candidates)
const resolved = resolveAuthorityConflicts(visible)
const fresh = updateTemperatureAndFreshness(resolved, state)
const retrieved = routeRetrievalIfNeeded(fresh, task)
const shaped = transformShape(retrieved)
const compressed = compressToBudget(shaped, budget)
const selected = enforceBoundaries(compressed, task)
return [
stableInstructions(selected),
projectRules(selected),
taskSummary(selected),
recentTail(transcript),
toolResults(selected),
currentUserInput(task),
]
}这里最重要的不是代码,而是思想:
Context 应该是被构建出来的,不是自然增长出来的。
自然增长的聊天历史,跑久了一定会变脏。
预算也不要只看总 token。更稳的做法是按桶分配:
| 预算桶 | 建议比例 |
|---|---|
| System / Policy / Project Rules | 10%-20% |
| Current User Input + Task State | 10%-20% |
| Recent Tail | 15%-25% |
| Retrieved Context | 20%-35% |
| Tool Results / Artifact Preview | 10%-20% |
| Long-term Memory | 5%-10% |
超预算时,不要第一反应就砍最近对话。
更合理的顺序通常是:
先删低置信度 retrieval
-> 再删过期 memory
-> 再把大工具结果转成 artifact 引用
-> 再压缩旧历史
-> 最后才缩 recent tail因为最近尾巴往往承载当前现场感,砍得太早,模型会突然变”远”。
MVP 可以按这个路线走:
| 版本 | 目标 |
|---|---|
| v0.1 | 最近 N 轮、任务状态 JSON、项目规则、artifact 外置、手动 compact、ContextPlan 日志 |
| v1.1 | 加 keyword / vector / hybrid retrieval 和 freshness filter |
| v1.2 | 加 memory namespace、TTL、冲突解决 |
| v1.3 | 加 subagent context、structured report、parent merge |
| v1.4 | 加多租户策略、权限感知检索、审计和 explain UI |
十、压缩摘要应该怎么写
很多系统的 compact 不稳,是因为摘要目标写错了。
它把摘要当成”前情提要”,而不是”接班材料”。
对 Agent 来说,更好的 compact 模板是:
用户目标:
[用户最初要完成什么]
硬约束:
[不能违反的规则、用户明确要求、权限边界]
当前状态:
[任务现在停在哪一步,不是泛泛总结]
关键事实:
[从文件、日志、工具结果里确认过的事实,带来源]
已读文件:
[文件路径 + 读到的重点 + 是否可能过期]
已改文件:
[文件路径 + 改了什么 + 为什么改]
已尝试但失败的方案:
[避免下一轮重复踩坑]
最近验证结果:
[命令、结果、失败信息或通过证据]
下一步:
[压缩后第一步应该继续做什么]这个模板的重点是”可继续执行”。
只知道历史没有用,Agent 必须知道下一步从哪里接上。
十一、选型时应该问什么
如果你在设计自己的 Agent 系统,不要先问”用哪个框架最强”。
先问这些问题:
我的 Agent 是低延迟补全,还是长任务执行?
任务状态能不能结构化?
工具结果会不会很长?
是否需要跨 session 记忆?
是否有多 Agent 协作?
是否需要企业权限和审计?
是否允许模型看到内部运行时状态?
失败后要不要恢复?
压缩后最怕丢什么?不同答案会导向不同设计:
- 如果是 IDE 补全,优先做局部代码上下文和低延迟索引。
- 如果是工作流任务,优先做 State、checkpoint 和可恢复执行。
- 如果是应用 SDK,优先区分 local context 和 LLM context。
- 如果是编程 CLI Agent,优先治理工具结果、压缩和最近尾巴。
- 如果是多 Agent,优先设计边界、角色、handoff 和结构化产物。
- 如果是长期个人助理,优先设计记忆分层、技能沉淀和过期策略。
- 如果是企业流程,优先把权限、审批、secret 和审计放进 context 体系。
这比直接比较”谁的模型更强”更接近工程现实。
十二、一句话总结
如果把这篇压成一句话:
Context Manage 不是把更多内容塞进模型,而是在有限窗口里持续决定:什么信息该被模型看到、以什么形态看到、什么时候看到、过期后怎么处理、空间不够时怎么压缩、任务中断后怎么恢复。
再压成六个词:
选择
注入
召回
压缩
隔离
恢复Claude Code、LangGraph、OpenAI Agents SDK、AutoGen、Cursor、Hermes、OpenClaw 这些项目看起来差异很大,但它们都在回答同一个底层问题:
当模型没有真正的记忆,
而任务又必须连续推进时,
外层系统怎样管理模型这一轮该看到的世界?这就是 Context Manage 的价值。
它不是 Agent 的附属功能,而是 Agent Harness 的核心能力之一。