Claude Code ソースコード解説シリーズ 第4章: コンテキスト管理
Claude Code がコンテキストを管理し、履歴を圧縮し、長いタスクの一貫性を保つ仕組みを解説します。
『Claude Code ソースコード解析シリーズ』第4章|Context 管理
前回の Prompt Runtime の記事で、Claude Code が毎ターン、システムプロンプト、プロジェクトメモリ、動的コンテキスト、ツール説明、履歴メッセージ、ツール実行結果を再構成していることを確認しました。
今回はさらに掘り下げます。
これらの情報が蓄積していく中で、Claude Code は何を残し、何を圧縮し、何を破棄するのかをどのように判断しているのか?
Context 管理について、多くの人はついこう考えがちです。
より多くの履歴をモデルに詰め込めばいい。この理解は半分しか合っていません。
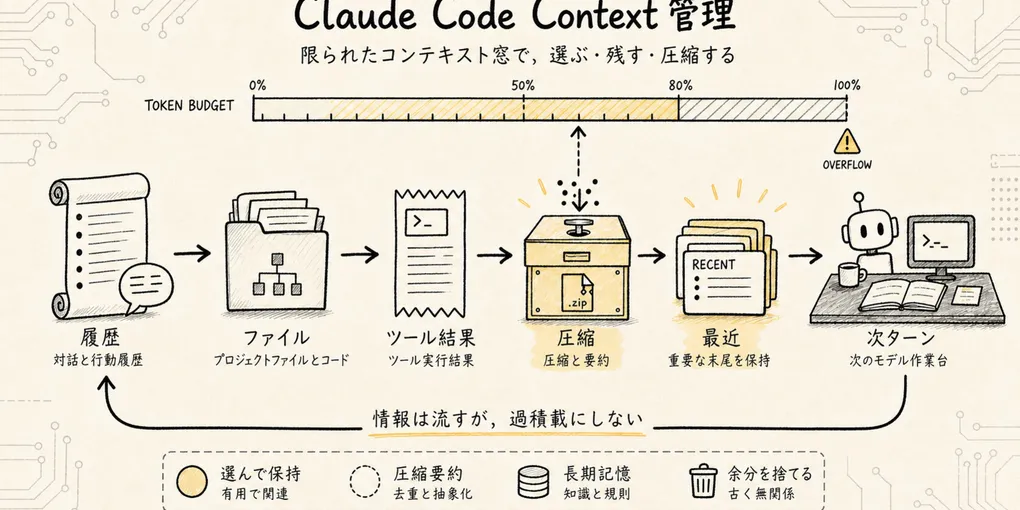
通常のチャットであれば、Context はたしかにチャット履歴のようなものです。しかし Claude Code はプログラミング Agent であり、その Context は動的な作業台に近いものです。モデルが毎ターン目にするのは「ユーザーが何を言ったか」にとどまりません。システムルール、プロジェクト規約、ツール説明、ファイル読み取り結果、コマンド出力、エラーログ、直前に変更したファイル、現在のタスクの進捗、さらに圧縮された履歴サマリーまで、すべてが並び得るのです。
本当の問題は「コンテキストを与えるかどうか」ではなく、次の点にあります。
ファイルを読み、コマンドを実行し、コードを修正し続ける Agent が、このターンでモデルに何を見せるべきかをどう決めるのか?古い情報はどう保持するのか?トークン枠が逼迫したとき、どう圧縮するのか?
前回の Prompt 構築が「モデルに操作マニュアルをどう組み立てて渡すか」だとすれば、今回扱うのはそのさらに下のレイヤーです。
モデルの作業台には限りがある。
Claude Code は作業を進めながら、同時に作業台を整理しなければならない。引き続き、このシリーズで使い続けている固定の例を用います。
ユーザー:このプロジェクトのテストが失敗している。原因を探して修正してほしい。この一文は短いですが、Claude Code にとってはすぐに長いタスクの連鎖へと展開します。
プロジェクト構成の確認
-> package.json の読み取り
-> テストコマンドの実行
-> エラー内容の分析
-> 関連コードの検索
-> 対象ファイルの読み取り
-> コードの修正
-> テストの再実行
-> 結果のまとめすべてのステップが新たなコンテキストを生み出します。Context 管理がやるべきことは、これらの情報を長いタスクの中で途切れさせず、かつモデルを情報過多で圧死させないことです。
1. Context は単なるテキストではなく、毎ターン組み直されるワークベンチである
まず前章の重要な前提を再確認しておく:モデルの各呼び出しは、それ自体ステートレスである。
したがって Claude Code が連続して作業できるのは、外側のハーネスが毎ターン「その時点で最も必要な作業現場」を再構成し、モデルに渡しているからに他ならない。
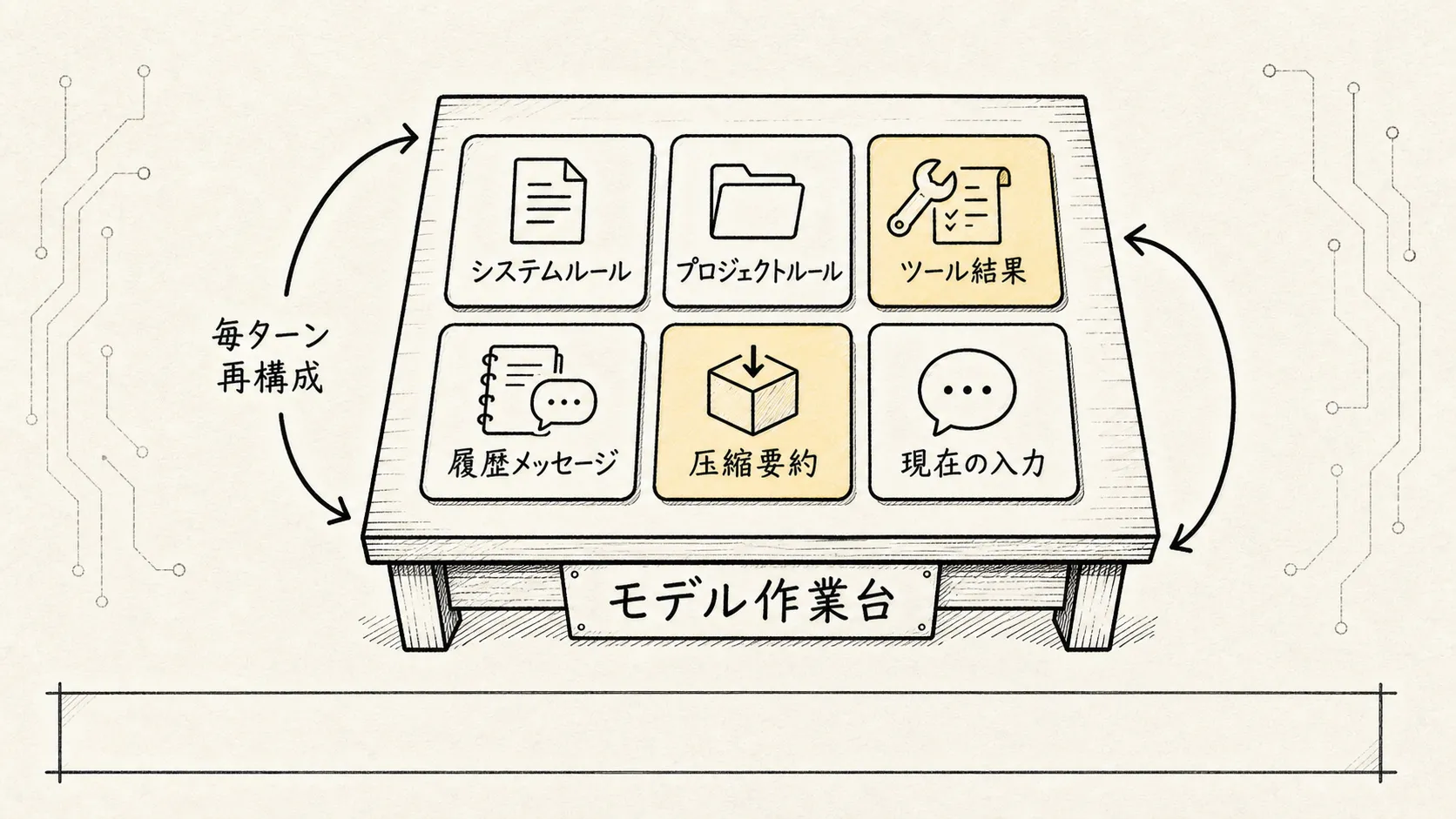
つまり、1 回のモデルリクエストは次のような単純な構図ではない:
ユーザーの質問 -> モデル実際は、これに近い:
システムルール
+ プロジェクトルール
+ ユーザー設定
+ 現在のツール仕様
+ 過去メッセージ
+ ツール呼び出し結果
+ 圧縮サマリー
+ 現在のユーザー入力
=> 今回のモデルリクエストこれが、Context 管理を「チャット履歴の保存」と捉えてはいけない理由である。より正確に名付けるなら:
コンテキストスケジューリング。
以下のような具体的な問いに答えなければならない:
- 毎ターン必ず保持すべき情報はどれか
- ランタイムにだけ存在し、モデルには露出すべきでない情報はどれか
- キャッシュ可能な情報はどれか
- モデルが必要になった時点で読み込めばよい情報はどれか
- どの過去のツール結果がすでに陳腐化しているか
- どの履歴をサマリーに圧縮すべきか
- 圧縮後も、モデルが自分が今何をしているのか把握し続けられるか
このレイヤーがなければ、ReAct メインループはすぐに次の二つの悪い結果に直面する:
少なすぎる場合:モデルが記憶喪失に陥り、これまでの経緯を把握できなくなる。
多すぎる場合:トークン爆発、コスト・レイテンシ・注意力がすべて制御不能になる。Context 管理とは、この二つの悪い結果のあいだでバランスを取ることである。
2. なぜプログラミング Agent のトークンは爆速で増えるのか?
通常のチャットでは、1 往復あたり数百トークンで済む。
プログラミング Agent は違う。アクションのたびに実環境の結果を持ち帰らなければならない。500 行のファイルは数千トークンになり、テスト失敗は長大なスタックトレースを返し、グローバル検索は数十件のマッチ箇所を吐き出す。
さらに厄介なのは、こうした情報は読んだあとすぐに捨てられない点だ。次のターンでもモデルは知っておく必要がある:
さっき読んだのはどのファイルか?
エラーは何行目で起きたか?
すでに試した手段は何か?
どのコマンドが失敗したか?
ユーザーから「この種類のファイルは変更するな」と言われていないか?したがって、Agent のコンテキスト増加は「会話が増えたから」という線形なものではない。ツール呼び出しが環境情報をメッセージ履歴に継続的に追記し続けるのだ。
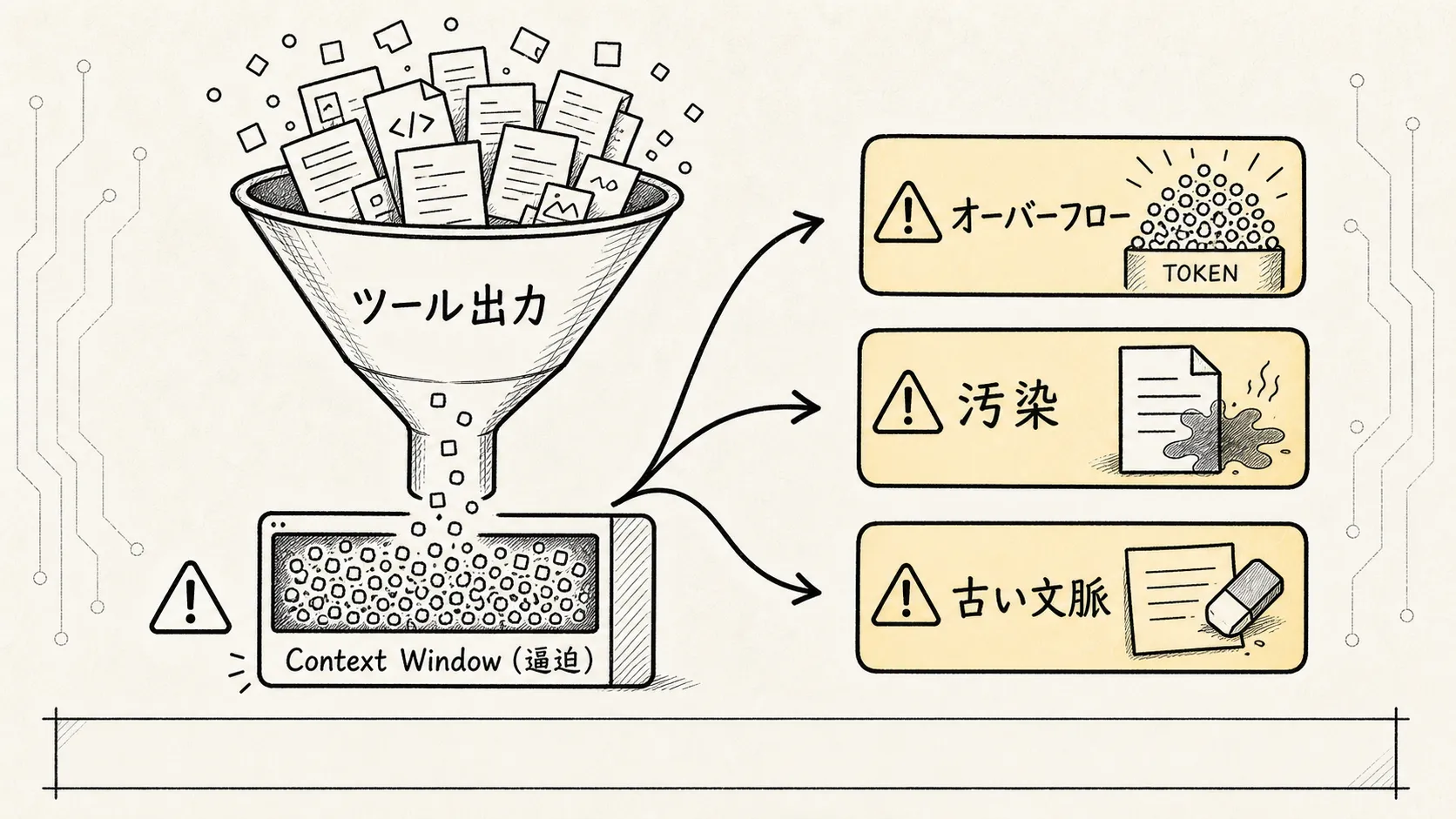
ここから、3 つの典型的な失敗が生まれる。
1. トークン爆発
ツールの実行結果が積み重なり、モデルへのリクエストがコンテキストウィンドウを超過する。この段階に至ると「回答の質が落ちる」では済まず、完全に停止する。
2. コンテキスト汚染
古いファイル内容、古いコマンド実行結果、古いエラーログがメッセージ内に残留し、モデルが過去の情報を現在の事実と誤認する。ファイルはすでに変更されているのに、コンテキスト上は旧バージョンのままなので、モデルは古いコードを前提に推論を続けてしまう。
3. 圧縮による記憶喪失
圧縮が粗すぎると、モデルはユーザーの当初の意図、現在のタスクの進捗、あるいは実行したばかりの操作を忘れてしまう。この記憶喪失が最も厄介だ——システムは動いているように見えるのに、方向性が知らず知らずのうちにずれていく。
だからこそ、Claude Code のコンテキスト管理は「いっぱいになったら要約する」ではなく、メインループの中で常時稼働するキャパシティガバナンスなのだ。
(実装上は、ヒープが溢れてから初めて full GC を走らせるのではなく、常駐の GC スレッドに相当する。)
3. Context を QueryEngine のメインループに組み込む
Claude Code のメインループは、単純にこうではありません。
モデルにリクエスト
-> ツールを実行
-> 再度モデルにリクエストそうではなく、毎ターン必ず Context ガバナンスの層を通過します。
プロジェクト情報とセッション情報をプリフェッチ
-> 今回のターンのコンテキストを組み立て
-> モデルにリクエスト
-> モデルの応答が回答かツール呼び出しかを判定
-> ツールを実行し、結果をメッセージ履歴に書き戻し
-> トークン量の負荷をチェック
-> 必要に応じてクリーンアップ、フォールド、圧縮
-> 新しい状態を引き継いで次のターンへ図にすると以下のようになります。
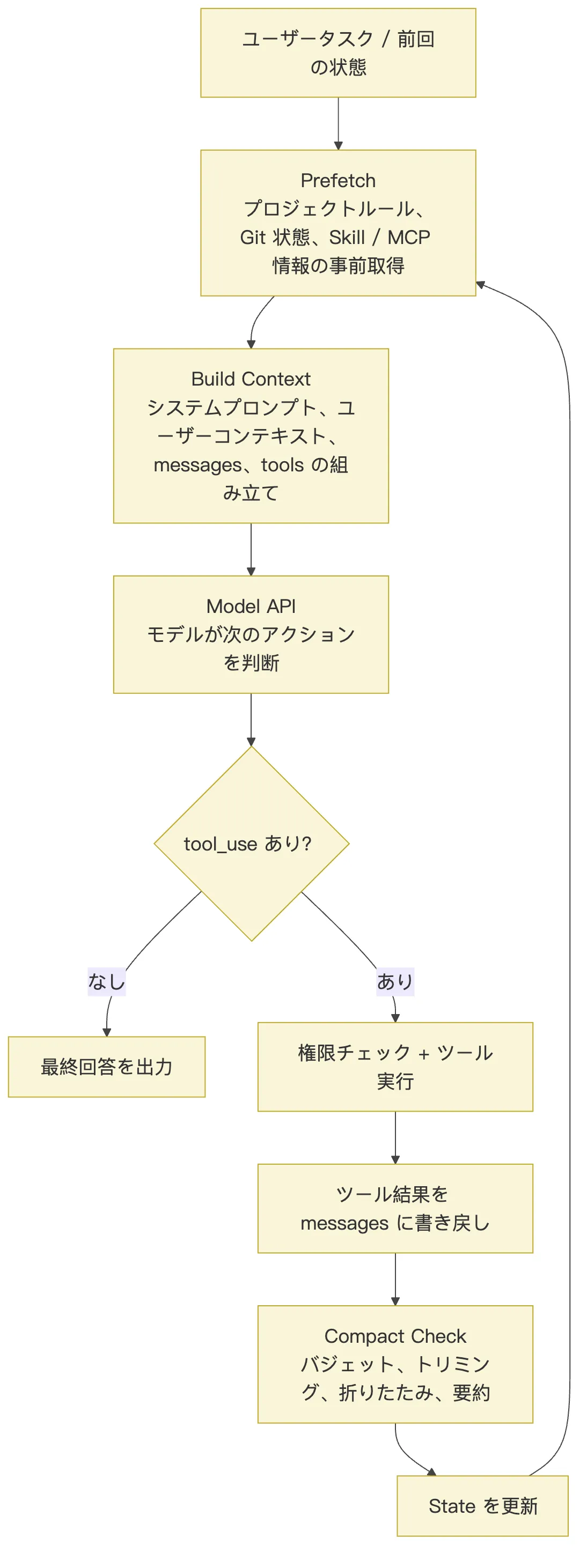
最も注目すべきは H -> I -> J -> B の流れです。
ツールの実行結果は、ただの UI ログではありません。次のターンの推論における原材料です。ファイルを読むたび、コマンドを走らせるたび、コードを検索するたびに、その結果はメッセージ履歴に書き戻され、そのうえで「この履歴はまだモデルに投入できる状態か」が評価されます。
Context 管理は QueryEngine の脇役的な補助機能ではありません。メインループを持続可能にするための前提条件なのです。
4. 情報ガバナンスがあって、その先に圧縮がある
「コンテキスト管理」と聞くと、多くの人はまず「圧縮」を思い浮かべる。しかし、成熟したエージェントは圧縮だけできればよいわけではない。
最低でも四つの問いに答えられなければならない。
第一に、可視性:
この情報はモデルに見せるべきか、それともランタイムだけに留めるべきか?APIキー、権限オブジェクト、内部トレースはプロンプトに入れるべきではない。大きなファイルやログも常に全体を含める必要はなく、参照や要約だけで十分なケースが多い。
第二に、優先順位:
システムルール、プロジェクトルール、ユーザー指示、長期記憶が衝突したとき、どれが優先されるのか?プロジェクトルールが「生成ファイルを変更するな」と定めているのに、ユーザーがモデルに生成物の直接修正を指示した場合、モデルの判断に委ねるわけにはいかない。
第三に、ホット・ウォーム・コールドの階層化:
どれが今まさに必要なホットコンテキストか?
どれが使うかもしれないウォームコンテキストか?
どれをいったん外に出し、必要になったら呼び戻すか?現在失敗しているテストログはホット。2時間前に修正済みの古いエラーはウォーム。全トランスクリプトはコールドであり、毎ターン詰め込むべきではない。
第四に、表現形式の変換:
同じ情報を、原文、要約、構造化された状態、差分、参照のどの形で保持すべきか?失敗ログはそのまま残すこともできるが、次のように抽出することもできる:
コマンド: pnpm test auth
状態: 失敗
主要エラー: TypeError: user.id should be string
関連ファイル: src/auth/session.ts
次のアクション: mock user の構築ロジックを確認この二つの形式では消費するトークン数がまったく異なり、モデルへの有用性も変わる。
コンテキスト管理とは情報ガバナンスであり、圧縮はその一要素にすぎない。
5. Claude Code の圧縮は一律ではなく、段階的な防御線である
ソースコードの分解を参考にすると、圧縮の連鎖は「軽量から重量へ」と進む一連の防御線として理解できる。
最初から過去の履歴を一文に要約するのではなく、まず低リスク・低ロスの局所的なクリーンアップを行い、それでも足りなければ折りたたみビューや全量要約へと段階的にエスカレートしていく。
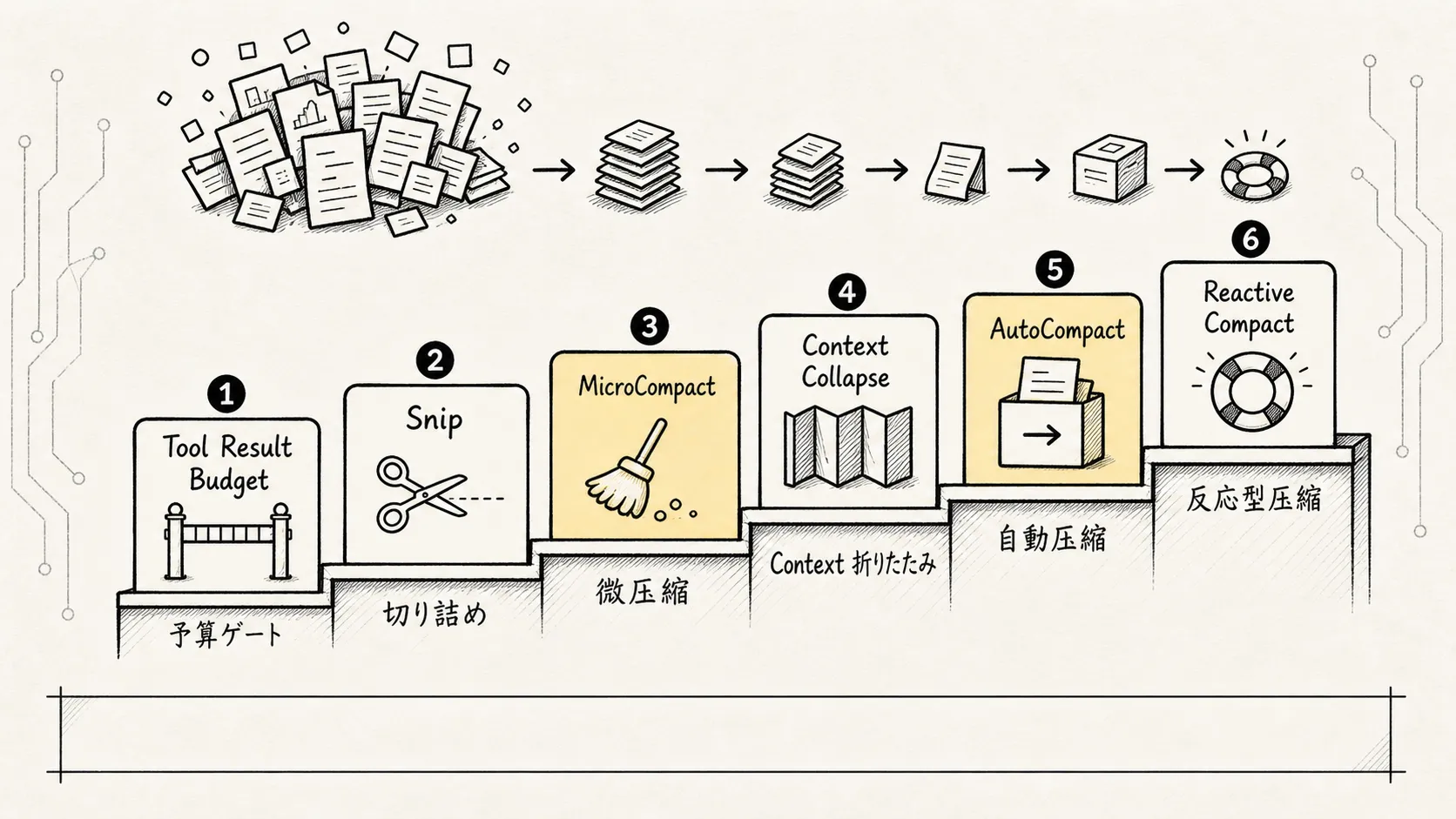
背後にある考え方は極めてシンプルだ。
局所的に削減できるなら、全体要約はするな。構造を保てるなら、要約だけで済ませるな。どうしても必要な最後の手段としてのみ、非可逆な折りたたみを行え。
以下、各層を分解して見ていく。
1. Tool Result Budget:最大のノイズ源を最初に制限する
最初に処理されるのは、通常ユーザーメッセージではなく、ツールの実行結果である。
- Bash が数千行のログを出力する
- Read が巨大なファイルを読み込む
- Grep が数十のマッチブロックを返す
- WebFetch がページ全体を取得する
こうした内容がそのまま次のターンに持ち越されると、ウィンドウはあっという間に埋まってしまう。applyToolResultBudget のロジックは、より重い圧縮が発動する前に、まず個々のツール結果のサイズを制御することにある。
ひとことで覚えるなら:
ひとつのツール結果に作業台全体を占有させるな。
2. Snip:構造を壊さずに低価値な内容を切り捨てる
snip は、より局所的な外科手術に近い。
会話全体を削除するのではなく、メッセージチェーンの構造を壊さないよう保ちながら、低価値な大きなブロックをマーカーや短い表現に置き換える。
なぜ直接削除してはいけないのか。メッセージ履歴にはツール呼び出し ID、tool_result の対応関係、前後のターン間の参照が存在するからだ。メッセージを直接削除すると、チェーンの連続性が破壊される。マーカーに置き換えることで、スペースを解放しつつ、「ここにツール結果があった」という構造を保持する。
ひとことで覚えるなら:
内容は短く、帳簿は切らさず。
3. MicroCompact:古いツール結果を掃除し、タスクの主構造は変えない
MicroCompact は、より体系的な局所クリーンアップである。
サイズが大きく、寿命が短く、後続のステップですでに上書きされたツール出力に対象を絞って処理する。具体的には:
古いファイル読み取り結果
古い検索結果
古いコマンド出力
古いWebページや外部クエリの結果通常は触れられない:
ユーザーの元のメッセージ
assistant の重要な応答
最新のツール実行結果
現在もアクティブなコンテキスト例を挙げよう。Agent がまず src/auth/session.ts を読み、その後このファイルを編集し、さらに新しいバージョンを再度読み取ったとする。最初に読んだ古い内容はすでに陳腐化している。それをそのままコンテキストに残し続けると、スペースを圧迫するだけでなく、モデルの判断を誤らせる可能性もある。
一言で覚えるなら:
ゴミは捨てるが、帳簿は書き換えない。
4. Context Collapse:まずはビューを折りたたみ、性急に全量要約しない
Context Collapse は、より賢い層だ。
目的は単純な履歴の削除ではなく、よりコンパクトなコンテキストビューへの射影である。折りたたんだ結果が安全なしきい値を下回れば、より高コストな AutoCompact を発動する必要はなくなる。
ここには、Claude Code の重要な工学的判断が表れている。
細粒度のコンテキストを保持できるなら、履歴を性急に大きな要約へと押し潰してはいけない。
全量要約はスペースを節約できるが、必ず情報の欠落を伴う。Collapse はむしろ、机の上の資料をまずグループ化し、折りたたみ、整理して収納するようなものであり、すべての紙を燃やして議事録一枚だけを残すようなやり方ではない。
5. AutoCompact:最終手段として履歴を引き継ぎメモに折りたたむ
ここまでの局所的な対策だけでは足りなくなった時点で、ようやく自動要約圧縮に入る。
ただし、ここでの要約が次のようなものであってはいけない。
テストの失敗について議論し、いくつかのファイルを読み、いくつかの修正を行った。こんな要約は、作業を続ける上で何の役にも立たない。
本当に有用な compact summary とは、タスクの引き継ぎメモのようなものであるべきだ。少なくとも以下を保持する必要がある。
ユーザーの主な要求
重要な制約条件
関与したファイル
読み取った重要な事実
発生したエラー
試行済みの修正
現在取り組んでいること
次にやるべきこと特に最後の二つは重要だ。
現在取り組んでいること
次にやるべきこと粗雑な要約の多くは「何が起きたか」だけを記録し、「タスクが今どこで止まっているか」を記録しない。圧縮後、モデルは大まかな経緯を知ることはできても、次にどこから再開すればよいかを見失ってしまう。
したがって、AutoCompact の本質は要約を書くことではない。
会話全体を、実行を再開できるタスク引き継ぎメモへと折りたたむことである。
6. Reactive Compact:「もう入りません」とモデルが悲鳴を上げたあとの最終防衛線
システムが事前に予算管理と自動圧縮を行っていても、現実の世界では想定外が起きる。
モデル API が返すコンテキストが想定以上に膨れ上がったり、メディアコンテンツが巨大だったり、トークン見積もりと実際のエンコード結果に乖離があったり——そんな時に必要になるのが reactive compact だ。これは事前の予防ではなく、エラー発生後の事後復旧であり、最後の安全網である。
その存在が示すのは、ただ一つのことだ。
長時間稼働するエージェントは、予算が常に正確であると前提してはならない。失敗したときの復旧パスを必ず持たなければならない。
これは、権限システムやツール実行システムにおけるリトライ/リカバリと同じ思想である。すなわち、決してエラーが起きないと夢想するのではなく、エラーが起きても引き戻せるように設計する、ということだ。
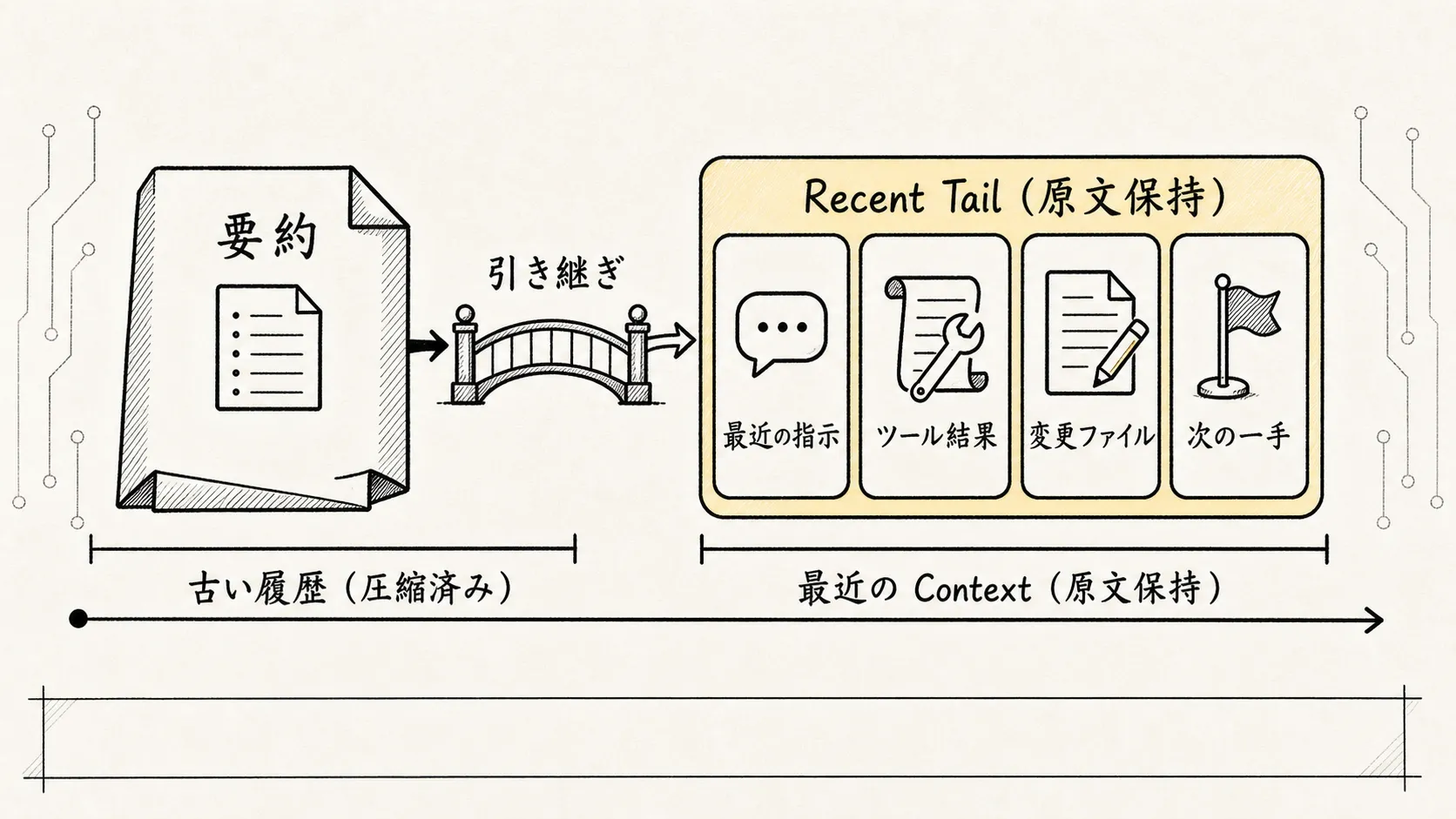
6. なぜ圧縮後も「最近の末尾」を残すのか?
圧縮で最も起きやすい問題は、モデルが過去を完全に忘れることではなく、「現場の手触り」を失うことだ。
圧縮前の最後の数ラウンドは、たとえば次のようなものになる。
さきほど src/auth/session.ts を編集した
さきほど pnpm test auth を実行した
さきほど新しい TypeError を確認した
ユーザーが「public API は変えないで」と補足したばかりこれらの情報は現在のアクションに最も近く、往々にして最も重要だ。もしこれがすべて要約に押し込まれてしまうと、モデルは次のラウンドでひどく「遠く」なってしまう——会議の議事録は読んだが、その場にはいなかった、という状態だ。
だから、より良いやり方はこうではない。
古い履歴 -> 要約ひとつ -> 続行ではなく、こうだ。
古い履歴 -> 要約ひとつ
+ 直近数ラウンドの生メッセージ
+ 直近の重要なツール実行結果
-> 続行これは Preserved-tail Relinking と呼べる。最近の末尾を残し、要約と現在の現場をつなぎ直す。
要約は過去の主線を担い、末尾は現在の手触りを担う。
長時間稼働するエージェントにとって、ひとつの重要な経験則がある。
圧縮とは、過去を覚えていることだけではなく、現在を受け止めることでもある。
7. Context・Memory・Transcript を混在させない
ここまで読むと、いくつかの用語が混同しやすくなる。Context、Memory、Transcript だ。
これらは別物である。
| 概念 | 平たく言うと | Claude Code における役割 |
|---|---|---|
| Context | 現在の作業台 | そのターンでモデルが実際に参照できる内容。リクエストごとに再構築される |
| Memory | 再利用可能なメモ | プロジェクトルール、ユーザー設定、セッション上の重要事実。ロードされて初めて Context に入る |
| Transcript | 完全な記録 | 全履歴の生ログ。復元・監査・リプレイに使われる。毎ターンそのままモデルに渡せるものではない |
次のように覚えるとよい。
Context:現在の作業台
Memory:再利用可能なメモ
Transcript:完全な記録Claude Code の Context 管理とは、これら三者の間で情報を絶えず運び続けることだ。
Transcript からは完全な履歴を保持し
Memory からは重要な事実を抽出し
いま最も必要な内容を Context に詰め込むTranscript を Context として扱うと、ターンごとにトークンが爆発する。
Context を Memory として扱うと、一時的なタスクの詳細が長期ルールを汚染する。
Memory を Transcript として扱うと、実際の実行プロセスの詳細が失われる。
この三つの境界が明確になれば、エージェントの「記憶喪失」問題の多くは説明がつくようになる。
8. 七次元モデルで見る Claude Code の到達点
Context 七次元モデル(Visibility / Authority / Temperature / Shape / Retrieval / Compression / Boundary)を借りると、Claude Code の完成度をより体系的に評価できる。
| 次元 | Claude Code の対応機構 | 完成度 | 限界 |
|---|---|---|---|
| Visibility(可視性) | system prompt、user context、toolUseContext、ツール結果バジェット、snip、collapse が連携し、モデルに渡す情報とランタイムに留める情報を切り分ける | 高い | すべての情報が統一された ContextItem に抽象化されているわけではなく、可視性の一部は依然として別モジュールに分散している |
| Authority(権威性) | system prompt の優先度、プロジェクトルール、ユーザーの現在の指示、権限ルール、セキュリティポリシーが裁定チェーンを形成する | 高い | 競合の解決は依然として prompt とランタイムルールの協調に大きく依存しており、独立した Authority Resolver ではない |
| Temperature(温度階層) | 直近のメッセージ末尾、現在のツール結果、Session Memory、Transcript / Resume がそれぞれ異なる温度層に対応する | 中程度〜高い | 温度による振る舞いの違いは存在するが、ソースコード上で Hot / Warm / Cold として明示的に命名されているとは限らない |
| Shape(情報形態) | 生のツール結果、切り詰めマーカー、要約メッセージ、boundary message、diff、構造化された tool_result など多様な形態が共存する | 高い | タスク状態はさらに構造化できる余地があり、多くの状態が自然言語の履歴に散在しているに過ぎない |
| Retrieval(検索・取得) | CLAUDE.md の読み込み、Git 状態、Read / Grep / Glob / Web / MCP / Skills によるオンデマンドな外部情報取得 | 中程度〜高い | ツール駆動・ファイル駆動の側面が強く、統一的ベクトル検索にデフォルトで依存する設計ではない |
| Compression(圧縮) | Tool Result Budget、Snip、MicroCompact、Context Collapse、AutoCompact、Reactive Compact による多層防御 | 非常に高い | 要約ドリフトは依然として本質的なリスクであり、そのため重要な制約・参照範囲・直近末尾の保持が不可欠である |
| Boundary(境界分離) | 権限チェック、Plan Mode、ツールプロトコル、子 Agent / fork、MCP 境界、Hooks、sandbox の発想 | 高い | マルチテナント、エンタープライズ権限、データ分離は具体的なデプロイ環境に依存し、Context モジュール単独で解決できるものではない |
この表で最も注目すべきは以下の点だ。
Claude Code の最大の強みは Compression と Boundary であり、最もエンジニアリングされているのは Shape と Retrieval、そして最も抽象化を進める余地があるのは Visibility / Authority / Temperature である。
言い換えれば、これは「チャット履歴を圧縮するだけの CLI」ではない。コンテキストガバナンスは QueryEngine、Prompt Runtime、Tool システム、権限システム、圧縮システム、セッション復旧システムに分散しており、それらが一体となって完全なハーネスを形成している。
とはいえ、教科書的な「独立した Context Manager」でもない。多くの機能は単一の ContextManager クラスに集約されておらず、メインループや複数のランタイムサブシステムに散在している。
これこそがソースコードを読む際に見落としがちな点だ。
“Context” という名前のファイルだけを探してはいけない。コンテキスト管理はメインループを横断するエンジニアリングリンクなのである。
9. ソースコードリーディングで掴むべきオブジェクト
最初からファイル名単位で孤立して読むのはおすすめしない。「コンテキストのライフサイクル」に沿って追う方がよい。
入力はどこから来るのか?
どの状態に入るのか?
どんなルールでフィルタされるのか?
いつ圧縮がトリガーされるのか?
圧縮後どこに書き戻されるのか?
次のターンでモデルはそれをどう再参照するのか?まずは以下のオブジェクト群を掴むとよい。
| 観察対象 | 主な問い |
|---|---|
| Query loop / query.ts | コンテキスト管理がメインループのどの位置で発生するか |
| ContextBuilder / Prompt Runtime | 今回のモデル入力はどの情報から構成されるか |
| CLAUDE.md Loader | プロジェクトルールとユーザーメモリがどうコンテキストに入るか |
| MessageStore / messages | ユーザーメッセージ、モデル応答、ツール結果がどう蓄積されるか |
| TokenBudget / tracking | どのような状況で容量が危険と判断されるか |
| Tool Result Budget / Snip | どのツール結果がまず局所的に切り詰められるか |
| MicroCompact | どの古いツール結果が削除対象になるか |
| Context Collapse | 全量要約ではなく、ビューをどう折りたたむか |
| AutoCompact / Reactive Compact | 履歴がどう構造化要約に置き換えられ、失敗時にどうフォールバックするか |
| Transcript / Resume | 生の履歴がどうバックアップされ、後続でどう復元されるか |
これらのオブジェクトを読むときは、「関数が何をするか」だけではなく、メインループ内での位置に注目する。
TokenBudget は単体で見ると単なる長さ計算ツールにしか見えない。しかし QueryEngine の中に戻すと、システムが「通常実行」から「圧縮管理」へ切り替わるタイミングを決める役割を担っている。
MicroCompact は単体で見ると単なるメッセージ掃除に見える。しかし長時間タスクの中に戻すと、古いツール結果が次のターンの判断を汚染し続けるのを防いでいる。
AutoCompact は単体で見ると単なる要約に見える。しかし Agent セッションの中に戻すと、次のターンのモデルに引き継ぎ可能な実行指示書を書き残している。
Agent のソースコードを読む上で重要な姿勢はこれだ。
「この関数は何か」ではなく、「この関数はループの中でどの制御不能を解決しているか」を問え。
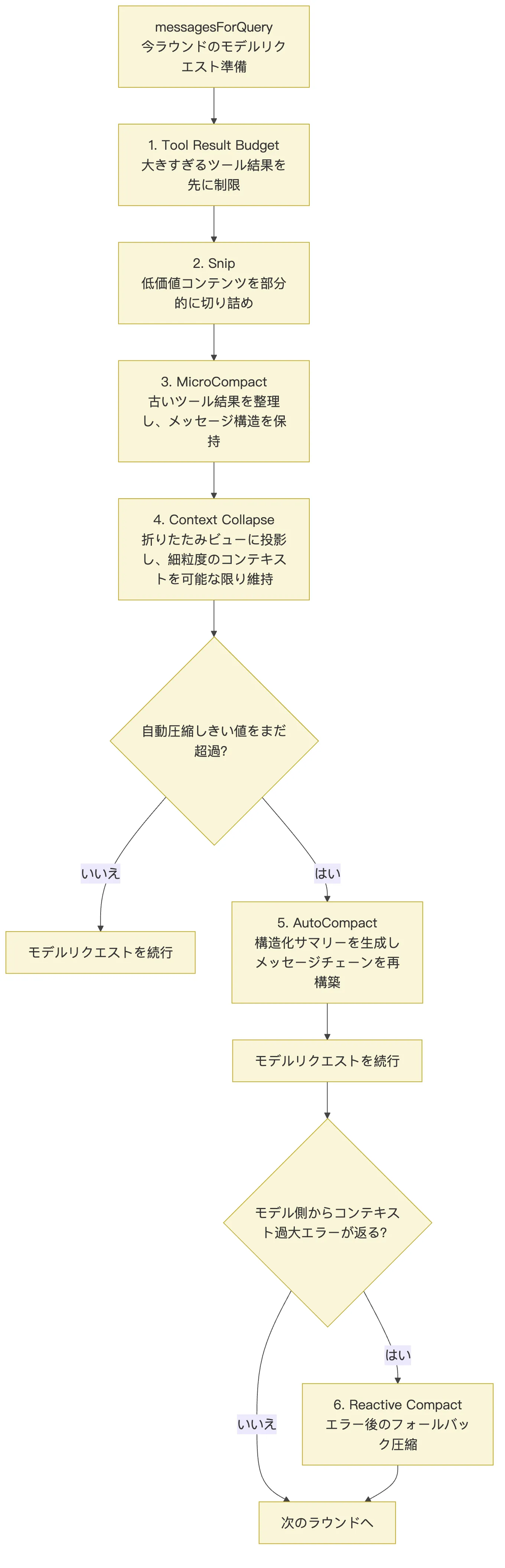
query.ts の 1 リクエスト分で見ると、Context 管理のソースコードパスは次の一本線に圧縮できる。
getMessagesAfterCompactBoundary()
-> applyToolResultBudget()
-> snipCompactIfNeeded()
-> microcompact()
-> contextCollapse.applyCollapsesIfNeeded()
-> autoCompactIfNeeded()
-> appendSystemContext()
-> queryModelWithStreaming()この一連の流れが示しているのは、コンテキスト管理が「API エラー発生後の後始末」ではなく、毎ラウンドのモデルリクエスト前に実施されるガバナンスだということだ。
なかでも applyToolResultBudget() は、最もバーストしやすい発生源であるツール実行結果を最初に処理する。Bash の出力ログ、大きなファイルの読み取り、MCP からの応答――これらはいずれも、チャット履歴よりも速くコンテキストを圧迫しうる。そのため Claude Code は、まずローカル予算でツール結果を制御し、その後にグローバルな圧縮を検討するという順序を取る。
microcompact と contextCollapse は中間層に位置づけられる。これらはローカルな履歴を可能な限り折りたたみ、射影し、整理することで、システムが早期に「要約一発」の状態へ退化するのを防ぐ。この振る舞いは重要だ。プログラミングタスクでは、「どのツール呼び出しがどの結果を生んだか」「どのファイルが読まれたか」「どのエラーが未解決か」といった構造を保持する必要があるからだ。
autoCompactIfNeeded() はより重量級の圧縮を行う。完全にコンテキストが埋まり切る前に、要約を出力するための空き領域をあらかじめ確保する。さらに、圧縮に失敗した場合のサーキットブレーカーも備えており、回復不能な圧縮リクエストが毎ラウンド再発されるのを防ぐ。
compact.ts では、圧縮後の再構築ロジックにも注目すべきだ。圧縮とは、履歴を単なる要約文に変換して終わり、ではない。compact boundary、サマリメッセージ、末尾の直近履歴、添付ファイル、hook の実行結果、さらには直近にアクセスされた重要なファイル群までを保存・復元する必要がある。これらが欠けると、次のラウンドでモデルは要約しか見られず、現在の作業コンテキストを見失いかねない。
もう一つ見落としやすい点がある。コンテキスト管理は各ツールの内部にも潜んでいるという点だ。たとえばファイル読み取りツールは、同じファイルの同じ範囲がすでに読まれており、かつファイルに変更がないことを検出すると、完全な内容を再度 messages に詰め込む代わりに file_unchanged を返す。この小さな最適化は、実は重複コンテキストによる汚染を減らすための工夫にほかならない。
したがって、このテーマをソースコードで追う際のアプローチは、「ContextManager というクラスを探す」ではない。情報がどのように流入し、予算管理され、折りたたまれ、圧縮され、そして再び復元されるか――このライフサイクルに沿ってコードを読むのが正解だ。
10. 最小限のContextマネージャを自作するなら、まず何から始めるか?
Mini Claude Codeを作ろうとするとき、最初から6層の圧縮パイプラインをすべて実装する必要はない。まずは最小構成から始めるとよい。
1. messages にユーザーメッセージ、アシスタントの返答、ツール結果を追記式で保存
2. 毎ターンのリクエスト前にトークンを見積もる
3. ツール結果が閾値を超えたら先に切り詰める
4. 直近 N ターンの生メッセージは保持する
5. それより古い履歴は構造化サマリに圧縮する
6. 生のtranscriptはディスクに書き出し、復元できるようにする
7. 圧縮サマリには必ず残す:ユーザーの目標、制約、変更済みファイル、失敗した試行、次の一手これだけでも、大半のデモ用Agentが数ターン回しただけで記憶を失う問題は解決できる。
本格的に進める段階になったら、次の要素を順次追加していく。
- プロジェクトルールとユーザーメモリの読み込み
- ツール種別ごとの予算配分
- ファイル内容の参照化とオンデマンド再読み込み
- 全量サマリではなくcollapseビュー
- サブAgent / forkによる長大な検索タスクの隔離
- 権限を考慮したコンテキスト注入
- ContextPlanログ(そのターンでなぜその情報を選んだのかを説明する)
この漸進的な進化の道筋は、「先に超大コンテキストモデルを繋ぐ」よりも安定している。
大きなコンテキストウィンドウが解決するのは容量の問題であって、情報規律の問題は自動では解決しない。Agentにとって本当に難しいのは、次の一点に尽きる。
情報が増え続ける状況で、
モデルに「いま最も見せるべき一小部分」だけを見せ続けられるかどうか。11. 一文でまとめる
この章を一文に圧縮すると:
Claude Code のコンテキスト管理とは、過去の履歴をどんどん詰め込むことではなく、限られたトークン空間の中で、組み立て・予算管理・切り詰め・折りたたみ・要約・再接続を継続的に行うことである。
さらに六つの単語に圧縮すると:
組み立て:毎ラウンド、モデルに何を見せるかを決める
予算管理:トークンの危険水域を検知する
切り詰め:大きすぎるツール結果を先に処理する
折りたたみ:できるだけ細粒度の構造を保持する
要約:最後に、実行を継続可能な引き継ぎメモを生成する
再接続:直近の末尾で現在の現場に接ぎ木するつまり、コンテキスト管理が本当に決めるのは:
Agent が第20ラウンドを超えても、
まだ連続して働いている人間のように振る舞えるかどうか。
「起きたばかりで、議事録だけ読んだ人」ではないかどうか。これこそが、Claude Code を「ツールを呼べるチャットボックス」から「長時間にわたってタスクを推進できるエンジニアリング Agent」へと変える、重要な仕組みの一つである。